

Introduction
The Apache TEZ® project is aimed at building an application framework which allows for a complex directed-acyclic-graph of tasks for processing data. It is currently built atop Apache Hadoop YARN.
The 2 main design themes for Tez are:
- Empowering end users by:
- Expressive dataflow definition APIs
- Flexible Input-Processor-Output runtime model
- Data type agnostic
- Simplifying deployment
- Execution Performance
- Performance gains over Map Reduce
- Optimal resource management
- Plan reconfiguration at runtime
- Dynamic physical data flow decisions
By allowing projects like Apache Hive and Apache Pig to run a complex DAG of tasks, Tez can be used to process data, that earlier took multiple MR jobs, now in a single Tez job as shown below.
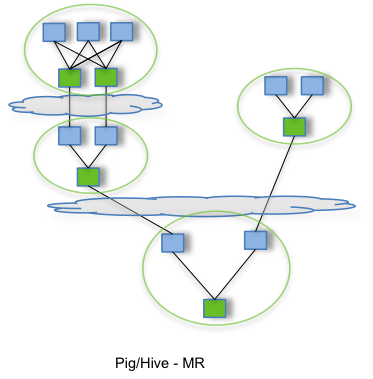
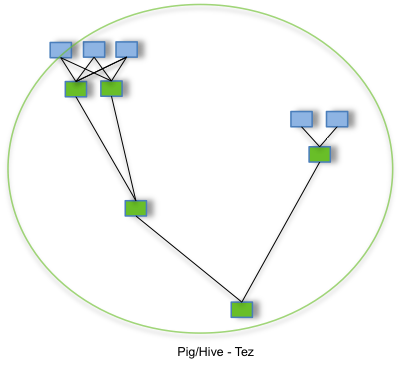
To download the Apache Tez software, go to the Releases page.